
Sample size considered for data checks
When tables contain more than 1 million rows, the DQC Platform automatically applies sampling to ensure data checks are efficient and scalable — without compromising relevance or statistical value.
The platform chooses the sampling method dynamically, based on the structure and distribution of the dataset.
How sampling works
The DQC Platform uses a decision-tree approach to select the most appropriate sampling method based on dataset characteristics:
1. Random sampling
Used when:
The dataset is uniformly distributed without clear subgroups.
Why:
Provides a simple, unbiased, and representative sample of the full dataset.
2. Stratified sampling
Used when:
The dataset contains distinct subgroups (strata) whose representation is important.
Why:
Reduces sampling error and ensures balanced coverage across key segments (e.g., departments, regions, product lines).
3. Systematic sampling
Used when:
The dataset is ordered (e.g., time series or spatial data).
Why:
Ensures even distribution across the range — e.g., one row per 1000 entries.
4. Cluster sampling
Used when:
The dataset is grouped into natural clusters (e.g. by geography or business unit), and it would be costly to sample every unit.
Why:
Efficient and cost-effective when full-row sampling isn't feasible.
Want to run checks on the full dataset?
If you prefer to include all rows in a table check — regardless of size:
Go to the More
Adjust the Table Check Scope to “No row limit”
Save and run the check as usual
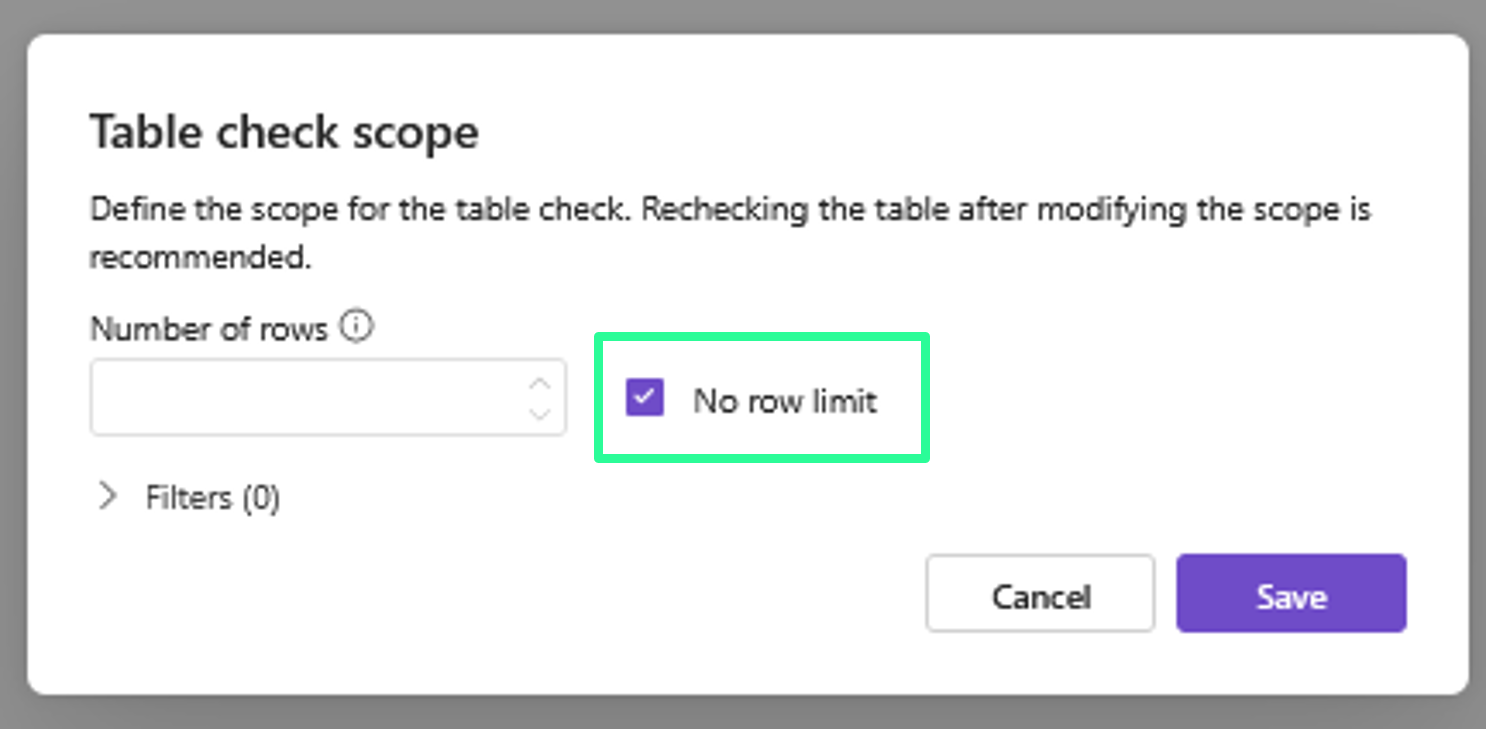 Full scans can be enabled manually where needed
Full scans can be enabled manually where needed
 Notes
Notes
Sampling only applies to tables with >1 million records
The sampling method is selected automatically and transparently
You can override the sampling by switching to full-table scope
Learn more: Adjustment of the Table Check Scope, Working with the Rules tab, Overview of existing rules