
Stichprobengröße bei Datenprüfungen
Bei Tabellen mit mehr als 1 Million Zeilen wendet die DQC Platform automatisch Stichprobenverfahren an, um Datenprüfungen effizient und skalierbar durchzuführen – ohne die Aussagekraft oder statistische Relevanz zu beeinträchtigen.
Die Plattform wählt das passende Verfahren dynamisch anhand der Struktur und Verteilung der Daten aus.
Wie das Sampling funktioniert
Die DQC Platform verwendet einen Entscheidungsbaum, um je nach Datensatzmerkmalen die geeignete Methode zu bestimmen:
1. Random Sampling
Verwendet, wenn:
Der Datensatz gleichmäßig verteilt ist, ohne erkennbare Untergruppen.
Warum:
Einfach, zufällig und repräsentativ – ideal für homogene Datenmengen.
2. Stratified Sampling
Verwendet, wenn:
Der Datensatz klar abgegrenzte Untergruppen (Strata) enthält.
Warum:
Minimiert Stichprobenfehler und stellt sicher, dass wichtige Segmente (z. B. Abteilungen, Regionen) angemessen abgedeckt sind.
3. Systematic Sampling
Verwendet, wenn:
Der Datensatz geordnet ist (z. B. Zeitreihen oder geosortierte Daten).
Warum:
Sorgt für gleichmäßige Verteilung über die Daten – z. B. jede 1000. Zeile.
4. Cluster Sampling
Verwendet, wenn:
Der Datensatz bereits in natürliche Cluster unterteilt ist (z. B. geografisch oder nach Geschäftsbereich) und eine Vollprüfung zu aufwändig wäre.
Warum:
Effizient und kostensparend, wenn eine Prüfung aller Einheiten nicht möglich ist.
Du möchtest die gesamte Tabelle prüfen?
Wenn alle Zeilen einer Tabelle geprüft werden sollen – unabhängig von der Größe:
Gehe zu More
Ändere den Table Check Scope auf “No row limit”
Speichern und Prüfung wie gewohnt starten
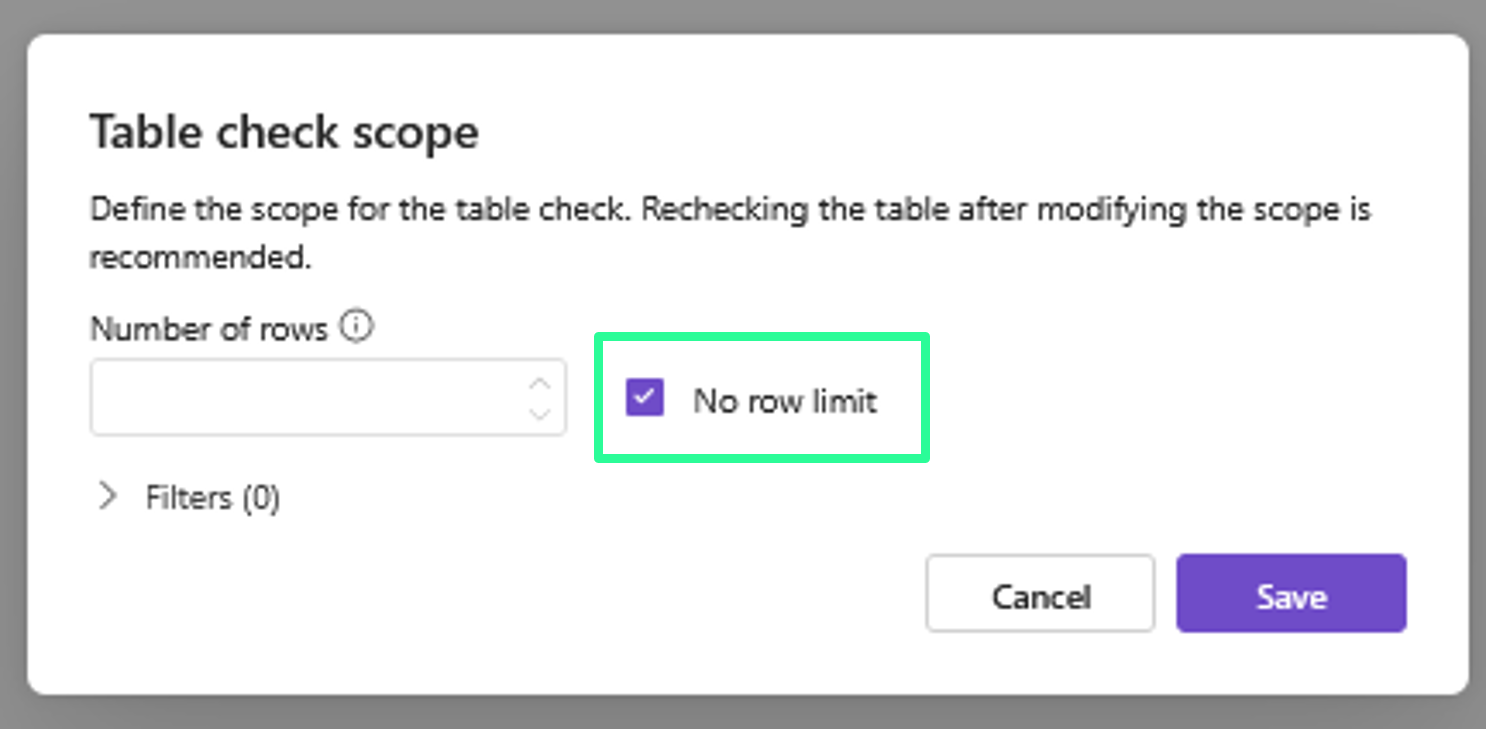 Vollständige Scans lassen sich bei Bedarf manuell aktivieren
Vollständige Scans lassen sich bei Bedarf manuell aktivieren
 Hinweise
Hinweise
Sampling gilt nur für Tabellen mit mehr als 1 Million Zeilen
Die Methode wird automatisch und nachvollziehbar ausgewählt
Über Table Check Scope kann jederzeit auf Vollprüfung umgeschaltet werden
Mehr erfahren: Adjustment of the Table Check Scope, Working with the Rules tab, Overview of existing rules