
Überblick über die Ist eindeutig-Regel
Die Ist eindeutig-Regel identifiziert doppelte Zeilen in einer Tabelle und markiert diese als Datenqualitätsprobleme. Sie kann auf eine oder mehrere Spalten angewendet werden und unterstützt sowohl exakte als auch unscharfe (fuzzy) Duplikaterkennung.
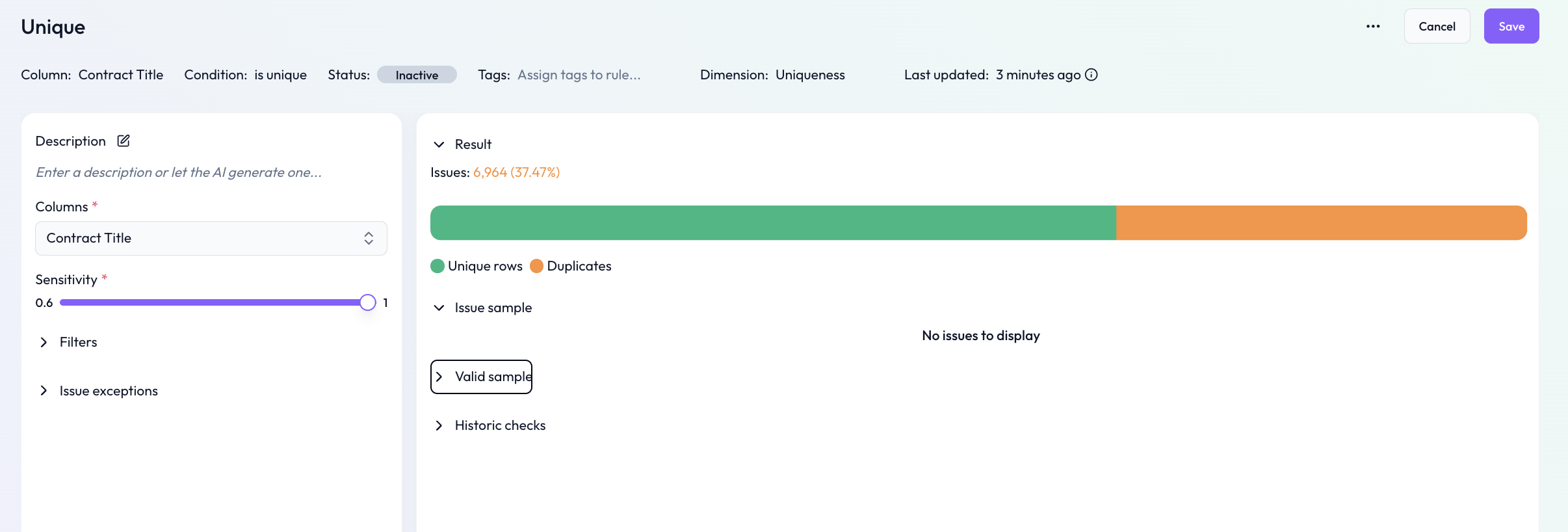
Funktionsweise des Matchings
Exaktes Matching (100 % Sensitivität)
Wenn der Sensitivitäts-Schieberegler auf 100 % gesetzt ist, sucht die Regel nach exakten Duplikaten:
Die ausgewählten Spalten werden pro Zeile zu einem gemeinsamen Vergleichswert kombiniert
Zeilen werden nur dann als Duplikat markiert, wenn diese kombinierten Werte exakt identisch sind
Die Ergebnisse sind vollständig deterministisch und bei jedem Lauf identisch
Dieser Modus eignet sich besonders für IDs, Schlüssel oder standardisierte Felder, bei denen Werte exakt übereinstimmen müssen.
Unscharfes Matching (60–99 % Sensitivität)
Bei einer Sensitivität unter 100 % nutzt die Regel eine Ähnlichkeitsschwelle, um sogenannte Near-Duplicates zu erkennen:
Die ausgewählten Spalten werden weiterhin zu einem String pro Zeile kombiniert
Anstelle exakter Gleichheit wird die Kosinus-Ähnlichkeit zwischen Vektor-Embeddings bewertet
Kleine Unterschiede wie Tippfehler, Abkürzungen oder Formatierungsabweichungen können erkannt werden
Der Schwellenwert definiert, wie ähnlich zwei Werte sein müssen, um als Duplikate zu gelten
(z. B. Schwelle = 0,90 erfordert 90 % Ähnlichkeit)
Erklärung des Approximate-Nearest-Neighbors-Algorithmus für Fuzzy Matching
Um ähnliche Werte auch bei großen Datenmengen effizient zu erkennen, verwendet die Regel einen Approximate Nearest Neighbors (ANN)-Algorithmus. Anstatt jede Zeile mit jeder anderen zu vergleichen, geht der Algorithmus wie folgt vor:
Erzeugt kompakte Vektor-Embeddings der kombinierten Strings
Grenzt potenzielle Duplikatkandidaten mithilfe von ANN-Indizes schnell ein
Vergleicht nur diese Kandidaten anschließend detailliert
Dieser Ansatz ermöglicht eine sehr performante Duplikaterkennung bei großen Tabellen.
 Notes
Notes
Bei 100 % Sensitivität ist die Duplikaterkennung vollständig deterministisch und liefert stabile, reproduzierbare Ergebnisse
Fuzzy Matching (< 100 %) nutzt ein Approximate-Nearest-Neighbors-Verfahren und kann bei großen Tabellen zu leicht abweichenden Issue-Counts führen
Für IDs und Schlüssel exaktes Matching verwenden, für menschlich gepflegte Daten wie Namen oder Adressen Fuzzy Matching einsetzen