
Medien
CRM Daten

Verbesserung der CRM-Daten und Skalierung von Anreicherungsprozessen mithilfe der DQC Platform
![]()
Steckbrief
 IOP Publishing ist ein wissenschaftlicher Verlag im Besitz von Fachgesellschaften, der der wissenschaftlichen Gemeinschaft Einfluss, Anerkennung und Mehrwert bietet. Das Portfolio von IOP Publishing umfasst mehr als 100 Zeitschriften, von denen etwa die Hälfte gemeinsam mit oder im Auftrag von Partnergesellschaften und Forschungsorganisationen herausgegeben wird. Das Portfolio von IOP Publishing spiegelt das Wachstum der Forschung in den Kernbereichen der Wissenschaft wider und trägt gleichzeitig dem zunehmend interdisziplinären Charakter der wissenschaftlichen Forschung Rechnung.
IOP Publishing ist ein wissenschaftlicher Verlag im Besitz von Fachgesellschaften, der der wissenschaftlichen Gemeinschaft Einfluss, Anerkennung und Mehrwert bietet. Das Portfolio von IOP Publishing umfasst mehr als 100 Zeitschriften, von denen etwa die Hälfte gemeinsam mit oder im Auftrag von Partnergesellschaften und Forschungsorganisationen herausgegeben wird. Das Portfolio von IOP Publishing spiegelt das Wachstum der Forschung in den Kernbereichen der Wissenschaft wider und trägt gleichzeitig dem zunehmend interdisziplinären Charakter der wissenschaftlichen Forschung Rechnung.

Ausgangslage
Warum spielt Datenqualität bei IOP eine wichtige Rolle?
Datenqualität ist für den Betrieb von IOP Publishing von entscheidender Bedeutung; unsere Organisation hat es sich zur Aufgabe gemacht, die Physik weltweit voranzubringen. Dies erreichen wir durch die Veröffentlichung hochwertiger Artikel in unseren Fachzeitschriften und durch hochwertige Metadaten, die sicherstellen, dass diese Artikel auffindbar sind.
Wie hilft die DQC Platform dabei, Herausforderungen im Bereich der Datenqualität zu bewältigen?
DQC hat unsere Fähigkeit, Datenprobleme zu identifizieren, deutlich verbessert; frühere Arbeiten in diesem Bereich erforderten viel Zeit, da Business- und IT-Teams gemeinsam die Regeln zur Datenqualität verfeinern mussten. DQC legt dies in die Hände der Business-Nutzer, sodass diese mit etwas Unterstützung Datenqualitätsprobleme schneller identifizieren können.
Übersicht über die allgemein angewandten Arten von DQ-Prüfungen
Wir haben mehrere Standardprüfungen durchgeführt (z. B. Lookups und Prüfungen mit regulären Ausdrücken wie E-Mail-Adressen), die uns geholfen haben. Die Verwendung von Unternehmensregeln hat uns dabei unterstützt, einige wiederverwendbare Datenqualitätschecks zu erstellen.

Deep-Dive
Ergänzung und Verbesserung von CRM-Einträgen durch korrekte persistente Identifikatoren
Für forschungsbezogene Organisationen wie Universitäten, Institute, Krankenhäuser, Förderer und Verlage dienen persistente Identifikatoren der weltweiten Standardisierung von Institutionsnamen und -strukturen. Sie spielen eine wichtige Rolle in den Bereichen CRM, Lizenzierung, Berichterstattung, Forschungsadministration und Datenintegration, da sie eine genaue Aggregation, die Verwaltung von Berechtigungen und die Interoperabilität über Veröffentlichungsworkflows hinweg ermöglichen.
Im Rahmen der routinemäßigen Datenpflege verglich IOP Publishing die in seinem CRM-System gespeicherten institutionellen Informationen mit der offiziellen Referenzdatenbank für persistente Identifikatoren. Wie bei vielen Organisationen, die große und langjährige Datensätze verwalten, zeigte sich dabei die Möglichkeit, die Qualität und Konsistenz der Kundendatensätze zu verbessern. Einige Einträge stimmten nicht mehr vollständig mit den neuesten Referenzdaten überein, während anderen noch kein persistenter Identifikator zugewiesen war.
Die Nutzung dieser Möglichkeiten zur Verbesserung der Datenqualität war wichtig, um mehrere zentrale Geschäftsziele zu unterstützen:
Genaue Abrechnung und Lizenzierung durch zuverlässigen Abgleich mit institutionellen Daten
Höhere Vertriebseffektivität durch klarere Kontostrukturen
Vertrauenswürdige Berichterstattung und Analysen über institutionelle Daten hinweg
Bessere strategische Planung auf der Grundlage zuverlässigerer Informationen
Verbessertes Kundenerlebnis durch weniger datenbezogene Fehler
Zur Unterstützung dieser Initiative nutzte IOP Publishing die DQC Platform, um Abgleichs-, Anreicherungs- und Validierungsabläufe zu automatisieren, wodurch der manuelle Aufwand reduziert und gleichzeitig die Datenqualität in großem Maßstab verbessert wurde.
Lösung
Zur Verbesserung und Anreicherung der CRM-Daten wurden drei Hauptschritte durchgeführt:
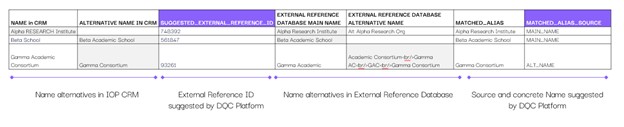
Anhand verschiedener Namenskombinationen zwischen dem CRM und der offiziellen Datenbank für persistente Identifikatoren wurden exakte Übereinstimmungen bei Namen und IDs ermittelt.
Es wurde ein mehrstufiger Fuzzy-Abgleich (z. B. Zeichen-Normalisierung, Kombinationen aus Editierabstand und tokenbasiertem Abgleich) zwischen den CRM-Einträgen und der Datenbank für persistente Identifikatoren durchgeführt, und ähnliche Einträge wurden abgeglichen.
Bei Fuzzy-Übereinstimmungen mit einer Erfolgswahrscheinlichkeit von unter ~85 % wurde empfohlen, die Beschreibung und die ID aus der von der DQC Platform bereitgestellten Datenbank für persistente Identifikatoren zu übernehmen, jedoch zuvor eine manuelle Bestätigung durchzuführen.
Diese Schritte wurden über agentische Verbesserungs- und Anreicherungs-Workflows in der DQC Platform implementiert. Es wurden zwei verschiedene Workflows für (1) fehlende persistente Identifikatoren und (2) nicht übereinstimmende Namen von Institutionen eingerichtet, die es ermöglichen, persistente Identifikatoren für bestehende CRM-Einträge automatisch abzugleichen, zu verbessern und anzureichern.
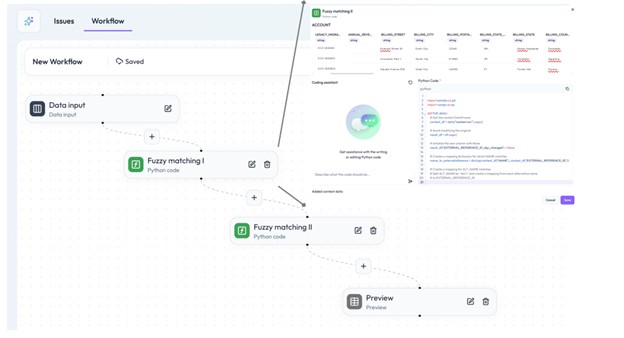 Die Ergebnisse der Optimierungsabläufe können als statische Datei heruntergeladen und die Einträge manuell überprüft werden. Anschließend werden die CRM-Einträge über einen Massen-Upload schnell aktualisiert.
Die Ergebnisse der Optimierungsabläufe können als statische Datei heruntergeladen und die Einträge manuell überprüft werden. Anschließend werden die CRM-Einträge über einen Massen-Upload schnell aktualisiert.
DQC verschaffte uns einen klaren Überblick über fehlende und inkonsistente persistente Identifikatoren in unseren Daten und ermöglichte so konsistentere und skalierbarere Verbesserungen. Es war zudem eine Freude, mit dem kooperativen und äußerst pragmatischen DQC-Team zusammenzuarbeiten.
James Gooding
Head of Data and Analytics
Auswirkung
Insgesamt konnte mithilfe der agentenbasierten Workflows der DQC Platform ein erheblicher Teil der zuvor nicht abgeglichenen Datensätze automatisch verbessert oder angereichert werden. Für weitere Datensätze wurden Empfehlungen mit hoher Konfidenz zur schnellen manuellen Bestätigung generiert, während nur ein kleiner Teil eine vollständig manuelle Überprüfung erforderte. Dies führte zu einer erheblichen Arbeitsersparnis bei gleichzeitiger Verbesserung der Gesamtqualität und Konsistenz der Daten.
Der automatisierte Abgleichprozess führte im Vergleich zu manuellen Suchen zu sofortigen und nachhaltigen Effizienzsteigerungen. Während der anfänglichen Datenanreicherungsphase wurden rund 100 Stunden manuelle Arbeit eingespart (entspricht etwa 5.000 £). Darüber hinaus reduzieren die etablierten Workflows den wiederkehrenden Aufwand um weitere 100 Stunden pro Jahr (entspricht etwa 5.000 £), da sie repetitive, nicht standardisierte manuelle Abgleichprozesse überflüssig machen.
Ausblick
Im Anschluss an diese Arbeit konzentrieren wir uns darauf, die wenigen Institute mit wenigen oder gar keinen Übereinstimmungen zu validieren und zu bereinigen sowie denselben Ansatz in die laufende Datenpflege zu integrieren, wobei wir DQC einsetzen, um den manuellen Aufwand zu reduzieren und die langfristige Qualität unserer Daten zu verbessern.
DQC Kundenerfolgsgeschichte
IOP Publishing x DQC