
Overview of the is unique rule
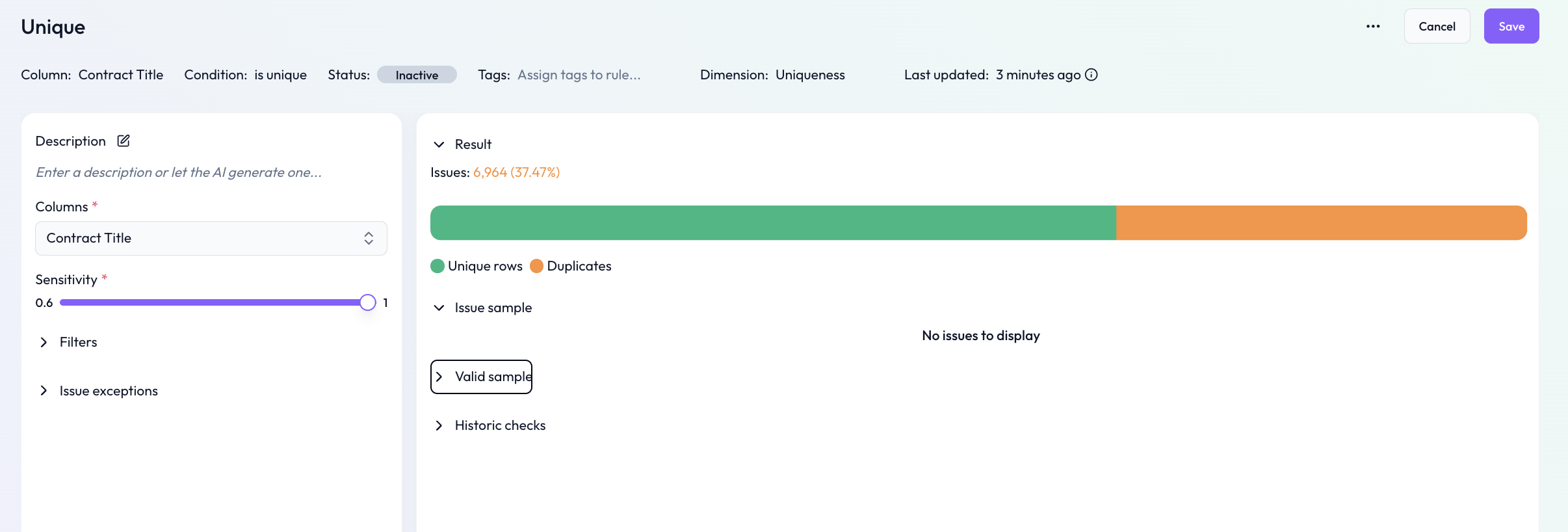
The is unique rule identifies duplicate rows in a table and marks them as data quality issues. It can be applied to one or multiple columns and supports both exact and fuzzy duplicate detection.
How matching works
Exact matching (100% sensitivity)
When the sensitivity slider is set to 100%, the rule looks for exact duplicates:
Rows are marked as duplicate issues only if these combined values are identical
Results are fully deterministic and repeatable across runs
This mode is recommended for IDs, keys, or standardized fields where values should match exactly.
Fuzzy matching (60–99% sensitivity)
The rule uses a similarity threshold parameter to detect near-duplicates based on semantic similarity.
Selected columns are combined into a single string per row
Instead of exact equality, cosine similarity between vector embeddings is evaluated
Small differences such as typos, abbreviations, or formatting variations can be matched
The threshold determines how similar items must be to be considered duplicates (e.g., threshold=0.90 requires 90% similarity)
Explanation of the approximate neighbors algorithm for fuzzy matching
To efficiently detect similar values at scale, the rule uses an approximate nearest neighbors (ANN) algorithm. Instead of comparing every row with every other row, the algorithm:
Creates compact vector embeddings of the combined strings
Quickly narrows down likely duplicate candidates using ANN indexing
Compares only those candidates in detail
Practical guidance
Use 100% sensitivity for strict uniqueness requirements and stable results
Use fuzzy matching when duplicates may differ slightly due to human input or inconsistent formatting
If exact reproducibility is critical, prefer exact matching or higher sensitivity values
 Notes
Notes
At 100% sensitivity, duplicate detection is fully deterministic and produces stable, reproducible results
Fuzzy matching (< 100%) uses an approximate nearest neighbors approach and may lead to slightly different issue counts on large tables
Use exact matching for IDs and keys, and fuzzy matching for human-maintained data such as names or addresses