
Media
CRM data

Strengthening institutional CRM data quality and scaling enrichment processes using the DQC Platform
 Company profile
Company profile
 IOP Publishing is a society-owned scientific publisher, providing impact, recognition and value for the scientific community. IOP Publishing’s portfolio includes more than 100 journals, around half of which are published jointly with or on behalf of partner societies and research organisations. IOP Publishing’s portfolio reflects the growth of scientific research in core scientific fields, while recognising the increasingly interdisciplinary nature of scientific research.
IOP Publishing is a society-owned scientific publisher, providing impact, recognition and value for the scientific community. IOP Publishing’s portfolio includes more than 100 journals, around half of which are published jointly with or on behalf of partner societies and research organisations. IOP Publishing’s portfolio reflects the growth of scientific research in core scientific fields, while recognising the increasingly interdisciplinary nature of scientific research.
General state of data quality at IOP
Why does data quality play an important role at IOP?
Data quality is essential for IOP Publishing to be able to operate; our organisation exists to expand the world of Physics. We do this by publishing high quality articles in our journals and ensuring the data that underpins this is essential. Ensuring our article metadata is complete and accurate helps make articles searchable via both traditional search engines and AI resources.
How is the DQC Platform helping IOP tackle data quality challenges?
DQC levelled up our ability to identify data issues; previous work in this space had taken a lot of time between business and technical teams to refine data quality rules. DQC puts this in the hands of users, so with some assistance, they can rapidly identify data quality issues.
Overview of general types of DQ checks applied
We have done several standard checks (e.g. lookups, date ranges and regular expression checks for things like email addresses) that have helped us – using company rules has helped us have some reusable checks.

Deep Dive
Enrich and improve CRM entries with correct persistent identifiers
For research-related organisations such as universities, institutes, hospitals, funders and publishers, persistent identifiers are used to standardise institutional names and structures globally. They play an important role across CRM, licensing, reporting, research administration and data integration by enabling accurate aggregation, entitlement management and interoperability across publishing workflows.
As part of routine data maintenance, IOP Publishing reviewed the institutional information held in its CRM system against the official reference database for persistent identifiers. Like many organisations managing large and longstanding datasets, this highlighted an opportunity to further strengthen the quality and consistency of customer records. Some entries were no longer fully aligned with the latest reference data, while others did not yet have a persistent identifier assigned.
Addressing these data quality opportunities was important to support several core business objectives:
Accurate billing and licensing through reliable institutional matching
Stronger sales effectiveness through clearer account structures
Trusted reporting and analytics across institutional data
Better strategic planning based on more reliable information
Improved customer experience through fewer data-related errors
To support this initiative, IOP Publishing used the DQC Platform to automate matching, enrichment and validation workflows, helping reduce manual effort while strengthening data quality at scale.
Solution
Three main steps were conducted to improve and enrich the CRM data:
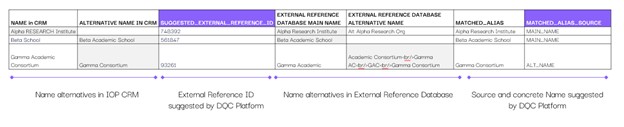
Exact name and ID matches were found using various name combinations between the CRM and the official persistent identifier database.
Multi-level fuzzy matching (e.g. character normalisation, combinations of edit distance and token-based matching) was performed between the CRM entries and the persistent identifier database, and similar entries were matched.
For fuzzy matches with a success probability of below ~85%, it was recommended to adopt the description and ID from the persistent identifier database offered by the DQC Platform, but to perform a manual confirmation first.
These steps were implemented via agentic improvement and enrichment workflows in the DQC Platform. Two different workflows for (1) missing persistent identifiers and (2) non-matching names of institutions were set up to automatically match, improve and enrich persistent identifiers for existing CRM entries.
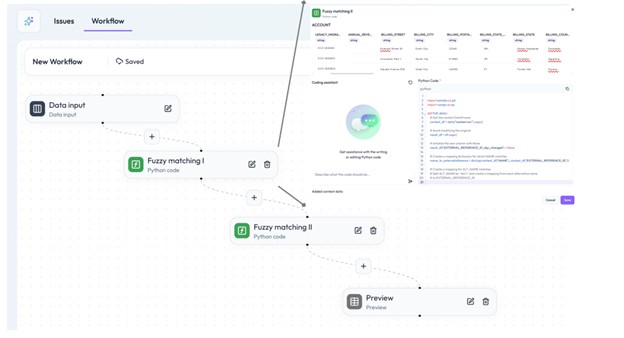
Results of the improvement workflows can be downloaded as a static file and entries can be manually confirmed. The confirmed CRM entries can then be updated quickly via bulk upload.
"DQC gave us clear visibility of missing and inconsistent persistent identifiers in our data, supporting more consistent and scalable improvements. It was also a pleasure working with a collaborative, highly pragmatic DQC team.”
James Gooding
Head of Data and Analytics
Impact
Overall, with the help of the DQC Platform’s agentic workflows, a substantial share of previously unmatched records could be automatically improved or enriched. For additional records, high-confidence recommendations were generated for quick human confirmation, while only a small proportion required fully manual review. This significantly reduced effort while improving the overall quality and consistency of the data.
The automated matching process led to immediate and sustained efficiency gains compared to manual searches. During the initial data enrichment phase, around 100 hours of manual work were saved (equivalent to approximately £5,000). Furthermore, the established workflows reduce recurring effort by a further 100 hours per year (approximately £5,000), as they eliminate the need for repetitive, non-standardised manual reconciliation processes.
Outlook
Following this work, we are focused on validating and resolving the small number of institutions with low-confidence or no matches, as well as embedding the same approach into ongoing data maintenance, using DQC to reduce manual effort and improve the long‑term quality of our data.
Download success story
IOP Publishing x DQC